
A twitter bot exploring the latent space, bias, stereotypes, and embedded vs projected meanings of word vector models such as Google’s Word2Vec.
This work was carried out while resident at, and with support from, Google’s Artists & Machine Intelligence program. I’m particularly grateful to have investigated the stereotypes and biases embedded in Google’s word models, funded by a Google Artist Residency 😉
I wrote about this project and its motivations in depth here, and supporting code can be found here.
This bot performs a random, unconditional search in the latent space of words. It picks completely random words, performs random vector arithmetic on them, and tweets the results. We the viewer are then left to try and interpret the results. Has the model learnt anything? Is there any real meaning in these results? Or are we just projecting ourselves back onto them.
E.g. (highly curated selection of results:)
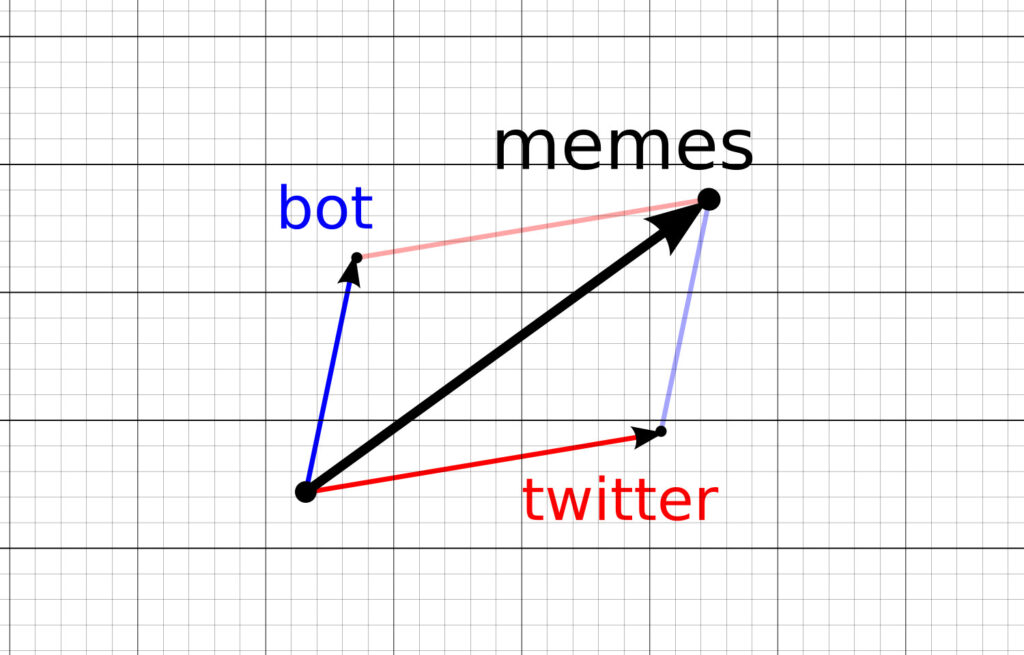
- twitter + bot -> memes
- human – god -> animal
- nature – god -> dynamics
- science + god -> animal
- love – sex -> adore
- sex – love -> intercourse, prostition, masturbation, rape
- authorities – philosopher -> police, governments
- beard – justified – space + doctrine -> theology, preacher
The bot is currently not active and is not generating new tweets, but is archived at twitter.com/wordofmath
Related Work
Also see @WordOfMathBias
Two technically similar, but otherwise unrelated twitter bots:
@spacedreamerbot: Nostalgic Space Dreamer Bot is trained on Apollo 11 Guidance Computer (APC) code, and generates endless code, exploring the latent space of APC, in the hope of one day being able to explore outer space.
@almost_inspire: every time the @DalaiLama tweets, this bot encodes the tweet into word2vec embedding space, adds noise, decodes and tweets.
Source code
I released a C++/openFrameworks library to load and play with word vector embeddings (mappings of words to high dimensional vectors), and supplementary python files to train / save / convert them. The downoad also includes a number of pretrained models including an optimised (and easier to use) version of the (in)famous Google News model. Download here: https://github.com/memo/ofxMSAWord2Vec.
Acknowledgements
Created during my PhD at Goldsmiths, funded by the EPSRC UK.
This work was carried out while resident at, and with support from, Google’s Artists & Machine Intelligence program. (I’m particularly grateful to have investigated the stereotypes and bias in Google’s word models, funded by a Google Artist Residency 😉